¿Qué es Business Intelligence?
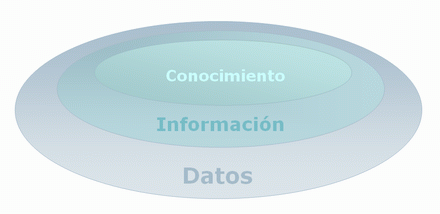
Business Intelligence es la habilidad para transformar los datos en información, y la información en conocimiento, de forma que se pueda optimizar el proceso de toma de decisiones en los negocios.
Desde un punto de vista más pragmático, y asociándolo directamente con las tecnologías de la información, podemos definir Business Intelligence como el conjunto de metodologías, aplicaciones y tecnologías que permiten reunir, depurar y transformar datos de los sistemas transaccionales e información desestructurada (interna y externa a la compañía) en información estructurada, para su explotación directa (reporting, análisis OLTP / OLAP, alertas...) o para su análisis y conversión en conocimiento, dando así soporte a la toma de decisiones sobre el negocio.
La inteligencia de negocio actúa como un factor estratégico para una empresa u organización, generando una potencial ventaja competitiva, que no es otra que proporcionar información privilegiada para responder a los problemas de negocio: entrada a nuevos mercados, promociones u ofertas de productos, eliminación de islas de información, control financiero, optimización de costes, planificación de la producción, análisis de perfiles de clientes, rentabilidad de un producto concreto, etc...
Los principales productos de Business Intelligence que existen hoy en día son:
Por otro lado, los principales componentes de orígenes de datos en el Business Intelligence que existen en la actualidad son:
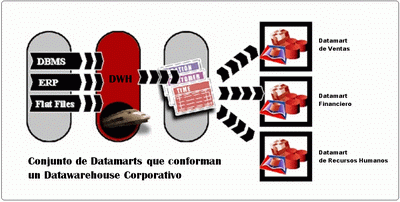
Datamart
Un Datamart es una base de datos departamental, especializada en el almacenamiento de los datos de un área de negocio específica. Se caracteriza por disponer laestructura óptima de datos para analizar la información al detalle desde todas las perspectivas que afecten a los procesos de dicho departamento. Un datamart puede ser alimentado desde los datos de un datawarehouse, o integrar por si mismo un compendio de distintas fuentes de información.
Datawarehouse
Un Datawarehouse es una base de datos corporativa que se caracteriza por integrar y depurar información de una o más fuentes distintas, para luego procesarla permitiendo su análisis desde infinidad de pespectivas y con grandes velocidades de respuesta. La creación de un datawarehouse representa en la mayoría de las ocasiones el primer paso, desde el punto de vista técnico, para implantar una solución completa y fiable de Business Intelligence.
La ventaja principal de este tipo de bases de datos radica en las estructuras en las que se almacena la información (modelos de tablas en estrella, en copo de nieve, cubos relacionales... etc). Este tipo de persistencia de la información es homogénea y fiable, y permite la consulta y el tratamiento jerarquizado de la misma (siempre en un entorno diferente a los sistemas operacionales).
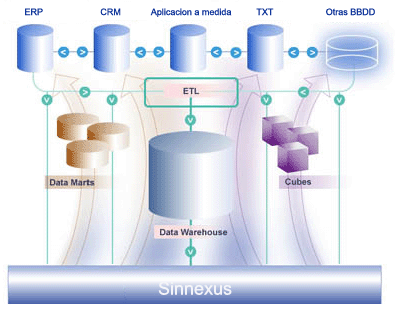
El término Datawarehouse fue acuñado por primera vez por Bill Inmon, y se traduce literalmente como almacén de datos. No obstante, y como cabe suponer, es mucho más que eso. Según definió el propio Bill Inmon, un datawarehouse se caracteriza por ser:
Por último, destacar que para comprender íntegramente el concepto de datawarehouse, es importante entender cual es el proceso de construcción del mismo, denominado ETL (Extracción, Transformación y Carga), a partir de los sistemas operaciones de una compañía:
Arquitectura de un Data Warehouse
Una arquitectura de Data Warehouse es una forma de representar la estructura global de los datos, la comunicación, los procesos y la presentación al usuario final. La arquitectura está constituida por las siguientes partes interconectadas:

Elementos que constituyen la arquitectura de un Data Warehouse
Explicamos uno a uno la función de cada nivel.
1. Base de datos operacional y base de datos externa
Las organizaciones adquieren datos de bases de datos externas a la propia organización, que incluyen datos demográficos, económicos, datos sobre la competencia, etc.
Mediante el proceso de data warehousing se extrae la información que está en la bases de datos operacionales y se mezcla con otras fuentes de datos. Enriquecemos la información.
2. Nivel de acceso a la información
Es la capa con la que trata el usuario final. La información almacenada se convierte en información fácil y transparente para las herramientas que utlizan los usuarios. Se obtienen informes, gráficos, diagramas, etc.
3. Nivel de acceso a los datos
Comunica el nivel de acceso a la información con el nivel operacional, es el responsable de la interfaz entre las herramientas de acceso a la información y las bases de datos.
La clave de este nivel está en proveer al usuario de un acceso universal a los datos, es decir, que los usuarios sin tener en cuenta la ubicación de los datos o la herramienta de acceso a la información, deberían ser capaces de acceder a cualquier dato del data warehouse que les fuera necesario para realizar su trabajo.
4. Nivel de directorio de datos (metadatos)
Para proveer de un acceso universal, es absolutamente necesario mantener alguna clase de directorio de datos o repositorio de información de metadato que ayude a mantener un control sobre los datos. El metadato aporta información sobre los datos de la organización, de dónde proviene, qué formato tenía, cuál era su significado y si se trata de un agregado, cómo se ha calculado éste.
Para mantener un almacén completamente funcional, es necesario disponer de una amplia variedad de metadatos, información sobre las vistas de datos para los usuarios finales y sobre las bases de datos operacionales.
5. Nivel de gestión de procesos
Este nivel tiene que ver con la planificación de las tareas que se deben realizar, no sólo para construir, sino también para mantener el data warehouse y la información del directorio de datos. Es o el controlador de alto nivel de los procesos que se han de llevar a cabo para que el data warehouse permanezca actualizado.
6. Nivel de mensaje de la aplicación
Este nivel es el encargado del transporte de la información a lo largo del entorno, se puede pensar en él como un middleware.
7. Nivel Data Warehouse (físico)
Es el núclo del sistema, el repositorio central de información donde los datos actuales usados principalmente con fines informacionales residen. En el data warehouse físico se almacenan copias de los datos operacionales y/o externos, en una estructura que optimiza su acceso para la consulta y que es muy flexible.
8. Nivel de organización de datos
Incluye todos los procesos necesarios para seleccionar, editar, resumir, combinar y cargar en eldata warehouse y en la capa de acceso a la información los datos operacionales y/o externos.
Estructura de un Data Warehouse
La estructura de un data warehouse se caracteriza por los diferentes niveles de esquematización y detalle de los datos que se encuentran en él.
1. Detalle de los datos actuales
Reflejan los acontecimientos más recientes, las últimas informaciones generadas por los sistemas de producción de la organización. El nivel de detalle no tiene por qué ser el mismo que el de los sistemas de producción, ya que los datos pueden ser fruto de alguna agregación o de una simplificación de los datos originales.
Una agregación es una partición horizontal de una relación según los valores de los atributos, seguida de una agrupación mediante una función de cálculo (suma, media, producto, etc)
2. Detalle de datos antiguos
Están almacenados en un nivel de detalle consistente con los datos detallados actuales, esto significa que si los datos actuales hacen referencia a ventas diarias en el año actual, los datos historiados contienen las ventas de años anteriores en el nivel de detalle de día también.
3. Datos resumidos
Son datos obtenidos como resultado de un proceso de síntesis de los datos actuales. Lo que se tiene entonces son datos agregados o resumidos. Por ejemplo, se entiende mejor la evolución de las ventas si se la presenta resumida por semanas que de manera diaria.
4. Metadatos
Ofrecen información descriptiva sobre el contexto, la calidad, la condición y las características de los datos. El metadato se sitúa en una dimensión diferente a la de los otros datos en el data warehouse, debido a que su contenido no es tomado directamente desde el ambiente operacional.
Diseño de datawarehouse
En el diseño de un data warehouse hay que partir de una serie de características, como ponía en el artículo Introducción a los Data Warehouse:
- Administra grandes cantidades de información
- Guarda histórico de datos
- Condesa y agrega información
- Integra y asocia información de varias fuentes
Para ello, hay que cambiar de los modelos E/R usuales en los operacionales, ya que de tipo de modelo de dato es complejo obtener datos acumulados e históricos. Usualmente se realizan una serie de procesos ETL, para obtener un modelo multidimensional y así poder realizar consultas analíticas de manera más optima.
Normalmente las consultas de análisis, se realizan sobre un hecho esencial a partir de una serie de parámetros. Un ejemplo serían las ventas con una serie de variables como tiempo, localización y producto.
- Número de ventas en un periodo determinado
- Evolución de las ventas
- Previsiones de venta
- Productos más vendidos en una zona determinada
Este tipo de modelo de datos consta principalmente de dos tipos de elementos:
- DIMENSIONES: Representan factores por lo que se analiza un determinado área del negocio. Son pequeñas y usualmente están desnormalizadas.
- HECHOS: Son el objeto de los análisis y están relacionados con las dimensiones. Son tablas muy grandes y suelen estar desnormalizadas. Se a menudo incluyen diferentes agregaciones como máximo, mínimo, media, …
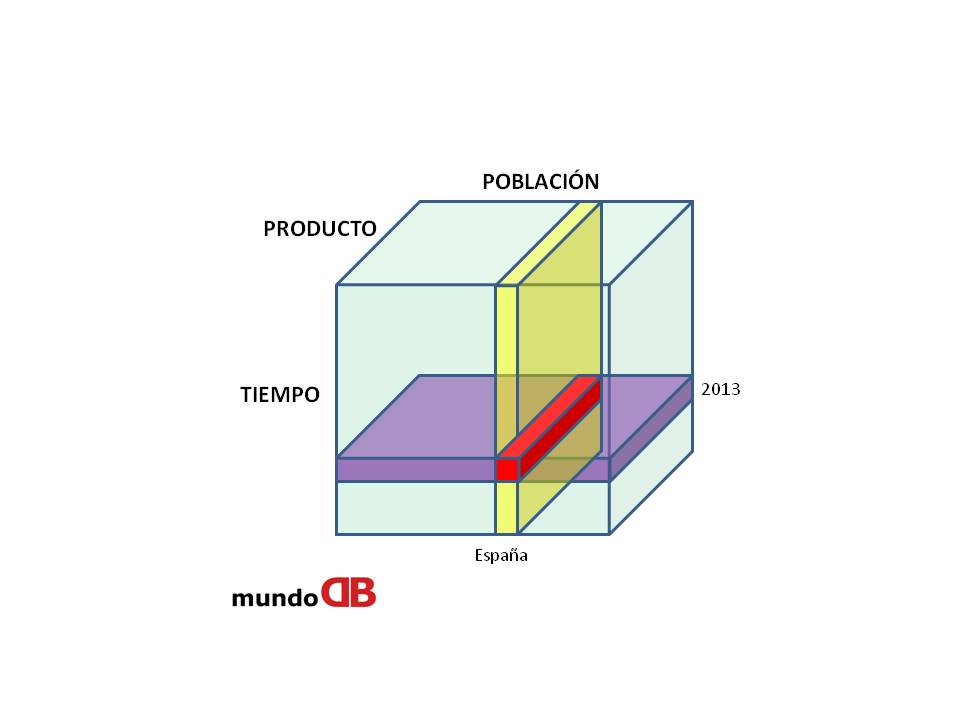
En una empresa de grandes dimensiones y sobre todo cuando hay múltiples data marts, es muy importante analizar las dimensiones previamente con las personas claves de las fuentes de datos, las personas claves de los datos finales y los diseñadores de otras personas involucradas en diseños corporativos de aplicaciones (data mart, generadores de informes, …), ya que las fuentes condicionarán los datos a proporcionar y las dimensiones se debería reutilizar en las distintas tablas de hechos de distintos data mart. Una dimensión tiempo debería de tener el mismo diseño en todos los data marts, porque si no cuando se integren será mucho más complejo. Es una decisión tanto técnica como política.
Los hechos deben de tener unidades de medidas uniformes: mismas localizaciones, unidades de tiempo o moneda, si no fuera así no se podría definir correctamente un hecho único.
Es importante no trabajar con claves significativas, para evitar problemas, por si existe cambios en el futuro, aunque esto habrá que valorarlo muy detenidamente, ya que podría perjudicar al rendimiento.
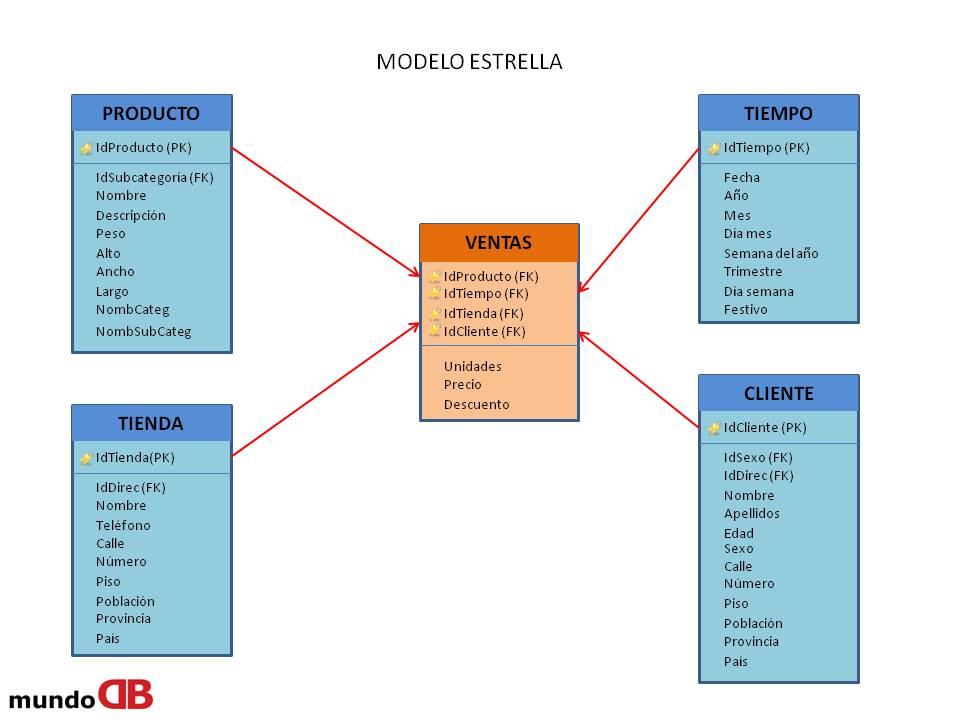
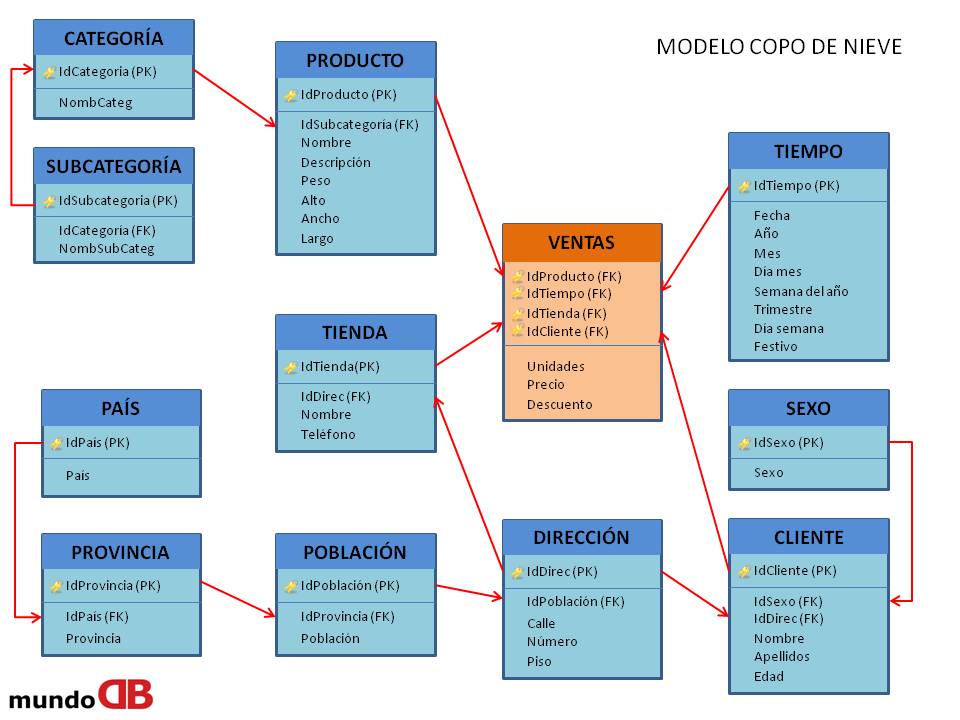
Un modelo multidimensional que no tiene jerarquías, se denomina modelo en estrella, si tuviera jerarquías, se denominaría modelo copo de nieve.
Datamining (Minería de datos)
El datamining (minería de datos), es el conjunto de técnicas y tecnologías que permiten explorar grandes bases de datos, de manera automática o semiautomática, con el objetivo de encontrar patrones repetitivos, tendencias o reglas que expliquen el comportamiento de los datos en un determinado contexto.
Básicamente, el datamining surge para intentar ayudar a comprender el contenido de un repositorio de datos. Con este fin, hace uso de prácticas estadísticas y, en algunos casos, de algoritmos de búsqueda próximos a la Inteligencia Artificial y a las redes neuronales.
De forma general, los datos son la materia prima bruta. En el momento que el usuario les atribuye algún significado especial pasan a convertirse en información. Cuando los especialistas elaboran o encuentran un modelo, haciendo que la interpretación que surge entre la información y ese modelo represente un valor agregado, entonces nos referimos al conocimiento.
Datamart OLAP
Se basan en los populares cubos OLAP, que se construyen agregando, según los requisitos de cada área o departamento, las dimensiones y los indicadores necesarios de cada cubo relacional. El modo de creación, explotación y mantenimiento de los cubos OLAP es muy heterogéneo, en función de la herramienta final que se utilice.
Se basan en los populares cubos OLAP, que se construyen agregando, según los requisitos de cada área o departamento, las dimensiones y los indicadores necesarios de cada cubo relacional. El modo de creación, explotación y mantenimiento de los cubos OLAP es muy heterogéneo, en función de la herramienta final que se utilice.

Datamart OLTP
Pueden basarse en un simple extracto del datawarehouse, no obstante, lo común es introducir mejoras en su rendimiento (las agregaciones y los filtrados suelen ser las operaciones más usuales) aprovechando las características particulares de cada área de la empresa. Las estructuras más comunes en este sentido son las tablas report, que vienen a ser fact-tables reducidas (que agregan las dimensiones oportunas), y las vistas materializadas, que se construyen con la misma estructura que las anteriores, pero con el objetivo de explotar la reescritura de queries (aunque sólo es posibles en algunos SGBD avanzados, como Oracle).
Pueden basarse en un simple extracto del datawarehouse, no obstante, lo común es introducir mejoras en su rendimiento (las agregaciones y los filtrados suelen ser las operaciones más usuales) aprovechando las características particulares de cada área de la empresa. Las estructuras más comunes en este sentido son las tablas report, que vienen a ser fact-tables reducidas (que agregan las dimensiones oportunas), y las vistas materializadas, que se construyen con la misma estructura que las anteriores, pero con el objetivo de explotar la reescritura de queries (aunque sólo es posibles en algunos SGBD avanzados, como Oracle).
Los datamarts que están dotados con estas estructuras óptimas de análisis presentan las siguientes ventajas:
No hay comentarios:
Publicar un comentario